
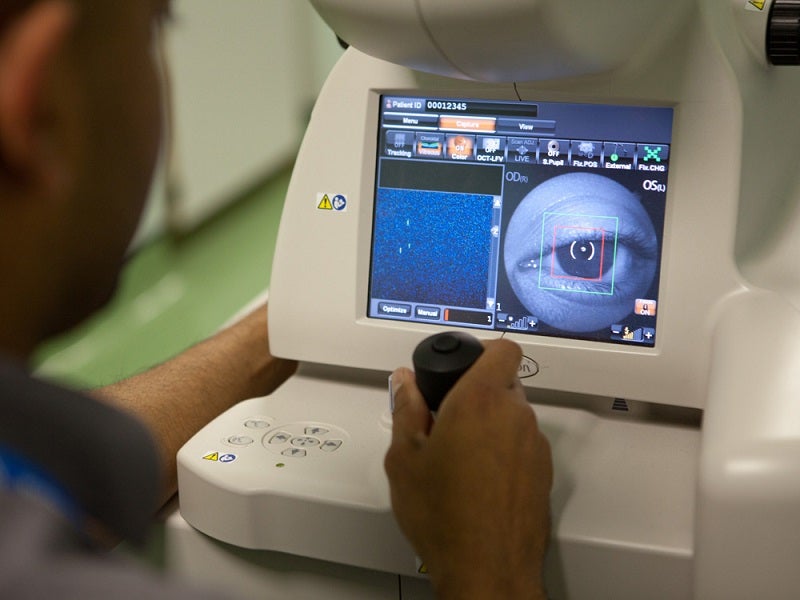
Since 2016, Moorfields Eye Hospital in London has been working with DeepMind, one of the world’s leading artificial intelligence companies. Through the partnership, researchers hope to use over one million anonymised retinal images to train artificial intelligence (AI) in the automated diagnosis of optical coherence tomography (OCT) images.
OCT images are extremely complex and can take clinicians a long time to analyse, which can impact how quickly patients can receive a formal diagnosis and start treatment. However, the open-access algorithm could one day be used to automatically diagnose eye diseases such as age-related macular degeneration and diabetic retinopathy, cutting down on patient wait times and potentially preventing blindness. Moorfields’ research team doesn’t need to learn to code, as the AI generates itself through user-friendly deep learning software.
Go deeper with GlobalData

Discover B2B Marketing That Performs
Combine business intelligence and editorial excellence to reach engaged professionals across 36 leading media platforms.
The technology has now been proven to match the accuracy of expert ophthalmologists and optometrists, and generate correct referral information. The AI’s diagnostic capacities were benchmarked against the decisions of clinicians at Moorfields Eye Hospital, demonstrating its real-world application.
The project is still in its early days, so Chloe Kent spoke to Moorfields Eye Hospital ophthalmologist Pearse Keane to find out more.
Chloe Kent: What is open-access AI?
Pearse Keane: Since 2012, we’ve had these big breakthroughs in AI, particularly related to deep learning. All of the big tech companies – Apple, Amazon, Microsoft, Google, Facebook – have moved to become AI-first companies. They’ve really been leading a lot of innovation in deep learning because they have access to this huge computing infrastructure. Until recently, there was only a very small number of people who had that expertise.
In healthcare, if you’re a consultant in the NHS your institution might have access to a lot of data, but unless you collaborate with industry there’s a big barrier to doing anything meaningful. What’s exciting is that since 2017 we’ve had these big breakthroughs in this thing called automated deep learning, the idea of AI systems that can build AI systems. Automated systems do all the hard work of designing an AI model, creating the architecture of the model and training and all of these things. And it’s not just that they make it; they automate, they make it easy for people who don’t have coding experience. If you want to use AI you can just use this software platform to train a model.
CK: How does it work?
PK: Say you have 1,000 photos of cats and 1,000 photos of dogs, and you want to train an AI on which is which. All you have to do is have a folder with all the images, and a spreadsheet which categorises them, saying “image one is a cat, image two is a dog” and so on. Upload it to the system, you have an application programming interface (API) which you could use.
That, for me, is a game-changer. It means that people like me, who do AI research but aren’t computer scientists, can actually start to do it ourselves and democratise the applications.
CK: How is this being applied in ophthalmology?
PK: We’re using it in research projects only. I think it’s still a few years away from being used in the care of patients and a lot of extra work would be required. But we’re wondering, for example, could we train an AI algorithm to look at a photo and see whether a patient might be eligible for a clinical trial or not?
We started out by getting five publicly available medical image data sets. We got photos of skin like moles and lesions, we got adult and paediatric chest X-rays, we got retinal scans from diabetic eye disease. We trained an algorithm using AutoML, Google’s open-source AI platform, and got pretty good results without any coding experience, comparable to state of the art for some of the datasets.
That’s been getting a lot of attention around the world from doctors in every medical specialty. I guess there’s this kind of hunger among doctors. We have thousands of ideas, we just don’t have the practical facilities to actually translate them into reality, and this maybe opens up that possibility.
CK: What is the most exciting project you can think of in this area right now?
PK: I think one of the hottest topics, not just in ophthalmology, but across healthcare and even outside healthcare is something called a generative adversarial network (GAN). GANs are neural networks that can mimic the distribution of any data set. What that means is they can effectively create images, sounds or videos that are synthetic. They can create photos of people that don’t exist, they can create some fake videos of politicians saying things they didn’t say, deep fakes and things like that. FaceApp, the Russian AI face editor which makes you look old, made me look so identical to my dad that my children thought it was their grandad.
Anyway, that technology actually has legitimate healthcare applications. If you’re studying a rare disease and you don’t have much data, there’s a chance you could augment your data using this. You could train your neural network just using synthetic images, and then you don’t have to worry quite so much about privacy concerns and data protection.
CK: What do you see as the best way to protect patient data in the age of AI?
PK: The single most important aspect I’ve learned is patient and public engagement and transparency about what you’re doing. If you tell people what you’re planning to do, and it’s clear it is or could be beneficial to them, then most people are reasonable and weigh up the risks versus the benefits. We have an area of the Moorfields website which has contact details of our information governance officer if people want to contact us to opt out of our research, and so far only ten or 15 people have contacted us to do so.
Of course, once we share anonymised data we’re not able to identify the patient again, so it’s not possible for us to remove it at a later point.
